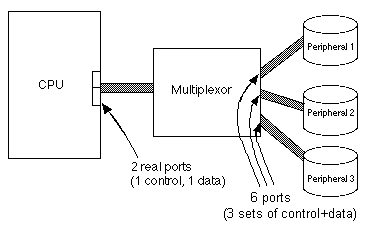
If each peripheral device occupies three ports, as shown in section 2 with the tape reader example, all of the chip's ports will quickly be consumed by a few devices. Many chips only have 4 or 8 ports simply because there isn't enough room on the edge of the chip for more metallic pads.
One mechanism that was used for a while is to multiplex peripherals through another level. A device would plug into two ports of the CPU and it would channel I/O commands to a variety of peripherals attached to it. Many mainframes used this method to connect a bank of terminals to the mainframe, or even several tape drives. Fig. 18.6.1 illustrates this.
The multiplexor could use one of several methods of identifying the recipient of the signals. The first, time division multiplexing, assigned time slots to each of the connected devices. If there were three tape drives connected to the CPU through a multiplexor, then during time slice 1, tape drive 1 would pass its signals through. During time slice 2, tape drive 2 would use the wires, and the multiplexor would electronically connect it to the CPU's port, and so forth. The multiplexor (and the CPU) must be faster than the attached devices in order for no signals to be missed. In the example of Fig. 18.6.1, the multiplexor should be at least three times faster than the disk drives. Another name for this method is round robin because the devices each get their turn in a circular fashion.
The other method, strangely named statistical multiplexing, allows the devices to be identified whenever a command for them arrives from the OS, and likewise when they sent data to the OS. An id number is appended to every command from the OS and every response from the device has an id number attached to it. This method makes more sense than round robin if not all the devices are equally active or if the attached devices are a little faster than they could be in round robin. An especially active peripheral might send a lot of data to the CPU while the others are inactive, and in statistical multiplexing it wouldn't have to wait until its next time slot rolled around.