Data is fetched from memory using the load instruction (LOD in the CSC-1). Conversely data is stored to memory using the store instruction (STD in the CSC-1). However, a computer that provides only these two instructions will be very limited and may not be able to implement any high level language.
In order to provide flexibility, indirect addressing allows the address to be created at run-time, often by adding two other numbers together. LOD and STD specify the address in the instruction itself, so the address can't be changed (unless the instruction is changed, which is possible but highly frowned on these days).
Most high level language data structures, such as arrays, records (structs), objects, linked lists, etc., require indirect addressing because the addresses cannot be known ahead of time and stuck into a LOD instruction.
For example, consider an array of 100 integers, named stuff.
int stuff[100];
Let's say we wanted to add the 1st and 2nd element. We would use the indexes 0 and 1 as follows:
sum = stuff[0] + stuff[1];
However, if you needed to get at all the elements, or if you wanted to access a random element, you would need an index variable, such as:
n = stuff[i];
The value in variable i can be changed as the program progresses. This number isn't known at assembly time, but must be computed at run-time as needed. This is precisely why arrays need indirect addressing. Only scalars can be addressed using LOD and STD because their addresses are known at compile-time.
Now let's look at indirect addressing in the CSC-1 in some detail. The two instructions that implement indirect addressing are
LDS -- load from memory using the Secondary register's
contents as the address; put value into A
STS -- store A's value into memory using the Secondary
register's contents as the address
This section will lead you through the details of how the LDS and STS instructions work, using the CSC-1 block diagram repeatedly, as was done in Section 7.6.
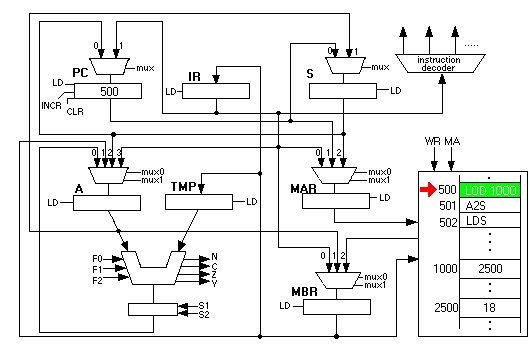
First, let us examine LDS. Below is the block diagram of the CSC-1 with a small program in memory and some data:
The "LOD 1000" instruction puts the number 2500 into the accumulator. There is nothing intrinsic about 2500 that says it is an address; it could be either a pure integer used for some calculation, or an address. The CSC-1 computer does not know the difference.
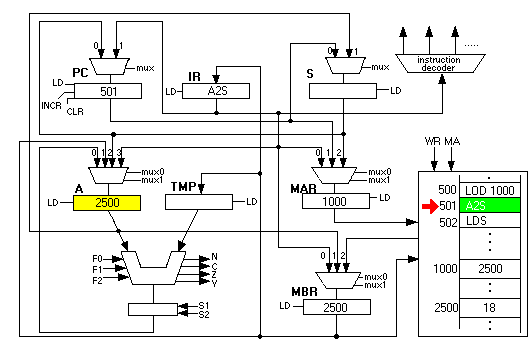
Next the A2S instruction fires up and copies the 2500 value from the A to the S register:
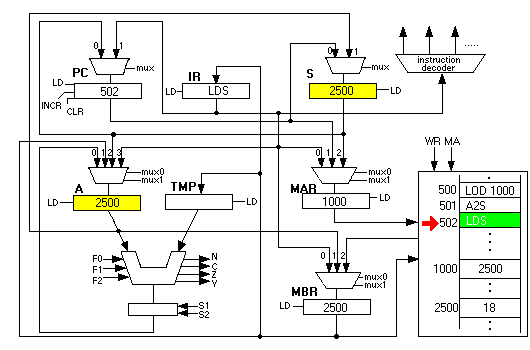
Now the fun begins. The next instruction is "LDS". This instruction first copies the contents of S into the MAR and initiates a memory read. Since 2500 is in the MAR, it is as if the CSC-1 computer had executed a "LOD 2500" instruction:
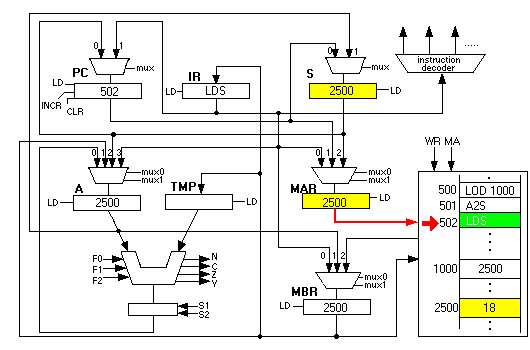
This copies the value at location 2500, which is 18, into the MBR:
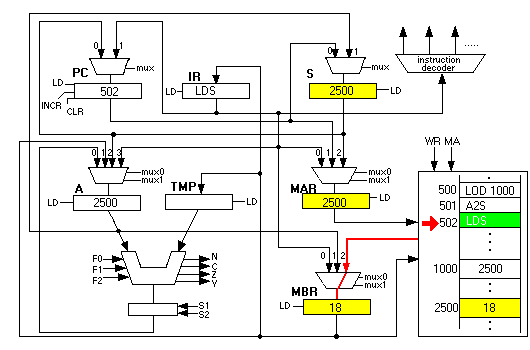
which is then copied into the A register to complete the instruction:
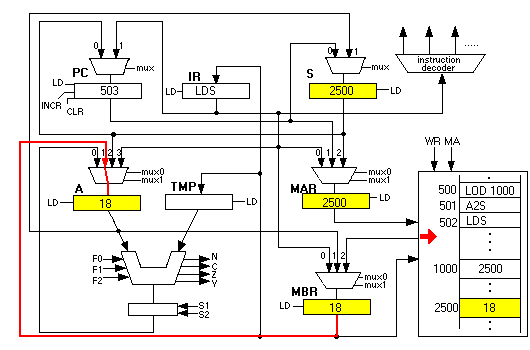
It is very important to realize that what has just occurred, the three instructions shown above, is equivalent to a single "LOD 2500." However, the "LOD 2500" instruction is fixed and cannot load from 2501, or 2502, as would be needed if this program were working through an array. The 3 instruction program that uses LDS could work through an array by changing the value at location 1000, to be 2501, then 2502, and so forth. We say that location 1000 is a pointer variable.
Some very old computers actually did change their load instructions. In this example, it would be as if the program went back and rewrote the lower 12 bits of the "LOD 2500" instruction so that it said "LOD 2501", then "LOD 2502," and so forth. In this way they were able to process an array. However, the program was altered permanently and could not be reused without changing the LOD instruction back to its original value, something that was too easy to forget to do! Hence, self-modifying programs quickly fell out of favor.
Let us now examine the converse, storing indirectly. Below is the set-up we will use. Notice that the number 192 is in A. This is just an integer, just a piece of data. The next instruction to be executed is STS. Location 1000, our pointer variable, contains 2500:
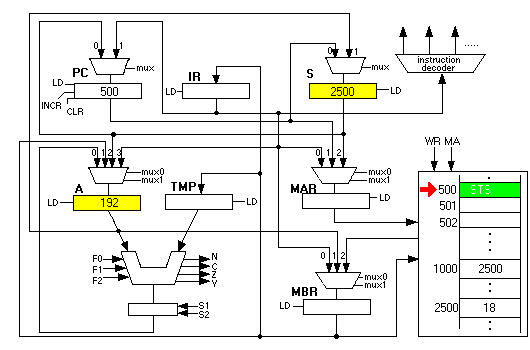
STS copies the S register into the MAR and also copies the value of the A register into the MBR, then initiating a memory write. When it is done, we see 192 in location 2500:
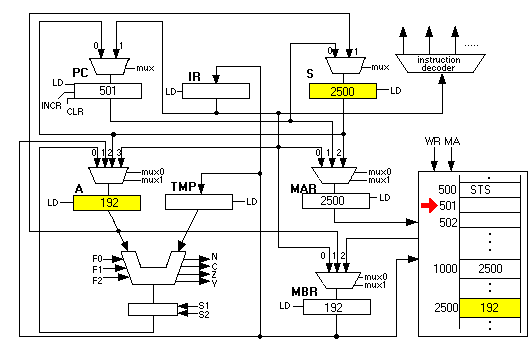
Finally, let us look at how the elements of an array would be summed up, without looking at the CSC-1 assembler program that does it. This will be shown in Chapter 9.
The picture below shows a 5-element array of small integers, in locations 2500 through 2504. A pointer variable is in location 1000, and it currently points to the first element of the array by having 2500 in it. A sum variable in location 1500 currently contains 0. When we are done, it will contain 8+2+1+4+6, or 21, which is the sum of elements of this array.
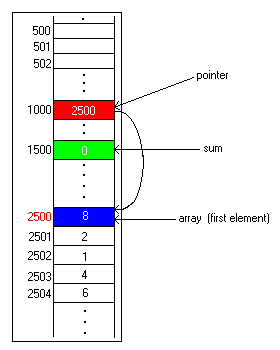
Not shown are two more variables. One would contain 5, since there are 5 elements in this array. Another would start out with 0, and would advance to 1, then 2, and so forth, up to 5. This variable is a counter and merely keeps track of how many numbers we have added up so that we don't go beyond the end of the array.
After 8 is added into the sum, the pointer is advanced by 1 so that it points to the next element of the array:
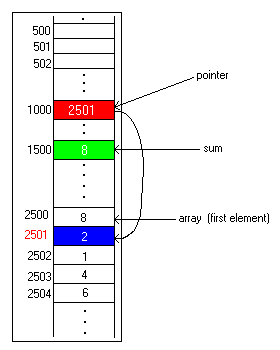
After 2 has been added to the sum, the same thing occurs:
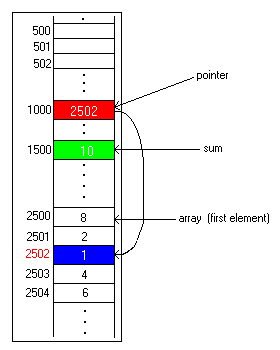
This keeps up until all 5 numbers have been added. The pointer will have 2505, which is not a legal member of this array, but the counter variable (not shown) will prevent the program from continuing. Below is the final picture:
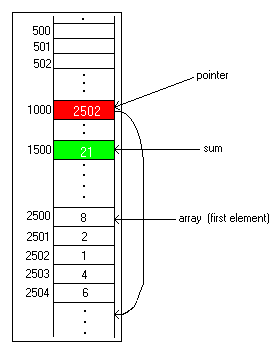
Arrays are not special. They are merely sections of memory that are treated by programmers as if they formed one entity. Computers like the CSC-1 do not even "know" that there is such a thing as an array! All that the primitive computer knows is that the machine language program forces it to access memory elements in this order. If a buggy program causes the program to go through its loop once too many times, the incorrect sum will result because a value beyond the end of the array will be added in. Worse, a program that changes elements of an array by rewriting them will clobber data that exists in memory locations beyond the "end" (highest address) of the array. These kinds of bugs are way too common and are the cause of lots of operating systems bugs and crashes.
What happens if the computer tries to access a memory address beyond the actual memory of the machine? A special kind of hardware error results that must be handled gracefully by the software without crashing the system, though the offending program must be squished and killed. In the CSC-1, it is impossible to ask to read or write a memory location beyond the beginning or end of memory, since there are 4096 words of memory, whose addresses go from 0 to 4095. The MAR is exactly 12 bits long, so the legal bit patterns are
000000000000 (0)
000000000001 (1)
...
111111111111 (4095)
In the CRC-1 computer, it is impossible to cause this kind of memory fault. Some UNIX systems call it a bus error, because an illegal address went out over the memory bus.
In many computers, the MAR is often longer than physical memory. Many computers have an MAR of 32 bits, which allows up to 4 gigabytes to be addressed. But few computers have 4 gigabytes of RAM, even today with continually falling memory prices. If a computer with 32-bit addresses has only 64 megabytes of RAM, then it is definitely possible for the MAR to get a number larger than 67,108,864 (64M), so a memory fault could occur and must be handled.