Having seen in detail how the LDS and STS instructions implement indirect address, let us now briefly look at how these instructions can implement a high level language data structure, such as an array.
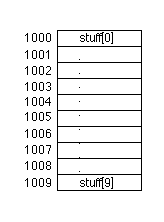
Imagine there is an array of 10 integers, called stuff. It is placed as location 1000 in memory when the program starts. Later the following C statement is executed:
stuff[i] = j;
where i and j are int variables.
Here's a picture of array stuff in memory:
Since the value of i is not known at compile time, it is impossible to create an STD instruction to copy j's value into stuff[i]. Instead, the address of stuff[i] must be calculated by adding the base address of array stuff, 1000, to the value of i. This type of activity is called address arithmetic.
The CSC-1 computer stores one integer in one word of memory. Many current machines which are byte-addressable use at least 4 words to store one integer, so the value of i would have to be multiplied by 4 to get the address of the right integer on these machines. Multiplication by 4 can be done efficiently by left shifting the value of i two bits.
Here is a segment of CSC-1 code to implement stuff[i]=j. Assume that variable i is stored at address 2000 and variable j is stored at address 2500.
LDI 1000 ADD 2000 A2S LOD 2500 STS
The first line above puts the address of the beginning of the array into A, &stuff[0] in C notation. ADD 2000 then adds the value currently stored in i. Now A has the address of the desired word but since A will hold j's value, this address is shuffled over to the S register by the A2S instruction. Next, j's value can be loaded into the A register by LOD 2500, and finally the STS instruction stores this value into the correct memory location given by the contents of S.
Addresses for memory reads (and writes) can only come from the PC register (when a new instruction is being fetched), or the IR register (when the operand's address is hard-coded into the instruction) or from the S register (when the address is computed at run-time.) Only the A register can get the results of an arithmetic calculation, so there must be communication between the A and S registers.
We might think we can shrink our machine a bit by allowing the A register to directly feed into the MAR, thereby doing away with the need for a separate S register. That would work for LDS, where the A register will get a new value anyway. But it would fail for STS, because the address must be available at the same time as the new value to be stored into memory. The PC and IR registers must not be tampered with, so the TMP or MBR registers are the only alternatives. For reasons of simplicity, the CSC-1 chooses not to use either of these, but to have its own separate address register instead, which it calls S. Other computers may do things differently.
Here is the control point sequence for STS, using the "long version" instead of the compressed variants.
1. MAR-MUX=01
2. MAR-LD=1
3. MAR-LD=0; MA=1; WR=0; MBR-MUX=10
4. MBR-LD=1
5. MBR-LD=0; MA=0; PC-INCR=1; IR-LD=1
6. IR-LD=0; PC-LD=1
7. PC-INCR=0; PC-LD=0 (SAME)
------------------------------------------------------
8. MAR-MUX=10; MBR-MUX=01 (NEW)
9. MAR-LD=1, MBR-LD=1
10. MAR-LD=0; MBR-LD=0; MA=1; WR=1
11. MA=0; WR=0
This instruction is shorter than ADD since there is no operand fetch stage. Only the lines after the dashed line are different from the ADD instruction; the first seven steps are identical, since they are the instruction fetch stage.
Since STS assumes that S already has the correct address and A already has the correct value to store, it copies these values into the MAR and the MBR respectively in steps 8, 9 and 10, and then starts up the memory in 10. Step 11 merely turns off the memory so that any further changes will not affect it.